
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 오라클아키텍쳐
- OracleGoldenGate
- DataGuard
- ActiveDataGuard
- linux
- 데이터가드
- Oracle 19c
- goldengate
- rman
- recovery
- SSH
- 오라클
- adg
- Installation
- 백업
- ogg
- 데이터베이스
- backup
- SILENTMODE
- oracle recovery
- 19c
- 오라클설치
- 오지지
- Oracle
- ORACLE19C
- oracle installation
- 오라클구조
- Database
- oracle goldengate
- 디비투
- Today
- Total
DoubleDBDeep
[ORACLE] 5. REDO & UNDO 본문
Redo
Redo log file - 데이터베이스를 위한 트랜잭션 log를 담고있다. 두종류가 있다 archived redo log file, online redo log file
. online redo log : 마지막으로 커밋된 시점까지 시스템을 복원하기 위해 사용됨
. archived redo log : online redo log file의 과거 내용 전체를 복제한 사본
오라클 database는 최소 두 개의 온라인 리두로그 그룹을 가지며 그룹별로 적어도 1개의 멤버(파일)을 가지고있다.
순환 방식으로 사용된다 그룹1에 있는 로그파일에 쓰기 시작하고 그 파일이 다 차면 그룹 2의 로그파일로 넘어가서 쓰고 .. 다시 .. 1 .. 2.. 1 ..2 이런식으로 순환
Undo
변경이 일어나기 전 상태로 되돌릴 수 있도록 생성하는 정보.
수행 중인 트랜잭션이나 sql이 실패하거나 rollback 요청을 하면 그 전 상태로 돌아가게 함
Undo는 물리적으로 복원하는게 아닌 논리적으로 복원하는 것
그래서 트랜잭션이 새로운 extent를 할당하는 insert문을 실행하면 이 트랜잭션을 rollback 한다고 해서 할당된 extent가 사라지지 않는다. >>> fragmentaion이 발생하는 이유
Redo와 Undo 작동 원리
ex 1. INSERT-UPDATE-DELETE 시나리오
insert into t (X ,y) values (1 ,1);
update t set x = x+1 where x = 1;
delete from t where x = 2;
INSERT - 처음 insert into t 에서 redo, undo를 모두 생성함.

변경된 언두 블록, 인덱스 블록, 테이블 블록이 조금씩 버퍼캐시에 캐싱되어 있고 각 블록은 리두로그버퍼에 있는 엔트리에 의해 보호된다.
여기서 시스템이 중단되면 ? insert 되기 전 상태로 처리됨
UPDATE - insert와 거의 같은 작업이 일어남. before이미지를 저장할 공간이 필요하므로 INSERT보다 UNDO 량이 큼.
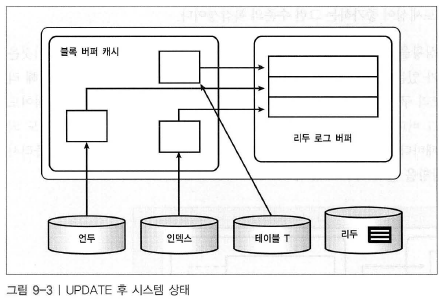
Buffer cache에 더 많은 undo segment block을 갖고있을 것
여기서 시스템이 중단되면 ? insert 되기 전 상태로 돌아감 , 트랜잭션이 커밋되지 않아 롤맥되고 버퍼캐시에 롤포워드된 언두를 가져와 데이터블록과 인덱스 블록에 적용해서 insert가 일어나기 전 상태로 되돌림.
DELETE - update와 유사 , 언두가 생성되며 블록은 변경되고 리두는 리두로그버퍼로 보내짐
COMMIT - 리두로그 버퍼 -> 디스크로 플러시

변경된 블록은 버퍼캐시에 있고, 이 트랜잭션을 재현하는데 필요한 모든 리두는 디스크에 안전하게 있으므로 영속적
SQL 명령어에서 NOLOGGING 설정
리두를 생성하지 않는다는 의미가 아니고 보통보다 적은 양의 리두를 생성한다는 의미
그럼 모든걸 NOLOGGING으로 하면 되는거 아니냐 ???? 안됨 ㅡㅡ
백업과 복구 시 LOGGING모드가 아니면 리두로그, 아카이브리두로그 모두 사용할 수 없음
즉
- 어느정도의 리두는 생성된다 : 데이터 딕셔너리를 보호하기 위한 것
- NOLOGGING은 이후에 일어나는 모든 작업이 리두를 안생성하게 하는것이 아님 나중에 DML은 다 로깅됨
- DIRECT PATH LOAD, INSERT APPEND는 로깅 안됨
segment 속성에서 NOLOGGING 설정
특정 작업 시 NOLOGGING 모드로 수행하도록 하는 것.
인덱스를 REBUILD하더라도 로깅되지 않음 (그인덱스만 , 테이블하고 다른 인덱스는 로깅됨)
LOG 경합
log file sync / log file parallel write 이벤트에 대한 write 시간이 길 때 리두로그 경합을 겪고 있을 수 있다 (리두 로그가 충분히 빠르게 기록되지 않는 상황)
왜발생?
1. app이 너무 자주 commit을 함
2. 디스크성능이 안좋음
3. 자주 액세스되는 다른 파일과 같은 디스크에 리두 저장
4. 디스크를 버퍼링 방식으로 마운트
5. 느린 raid 기술로 redo 저장

ORA -01555: snapshot too old Error
ORA-01555는 데이터 훼손이나 데이터 손실괴는 아무 관련이 없다 그런 점에서는 ‘안전한’ 오류다 단지 이 오
류를 만나는 순간 쿼리를 계속 진행할 수 없을 뿐이다.
원인
1. 작업량에 비해 UNDO SEGMENT가 너무 작다.
2. 데이터를 FETCH 하는 중간에 COMMIT 하도록 프로그래밍했다.
3. 블록 클린아웃
'ORACLE > Architecture' 카테고리의 다른 글
| [ORACLE] 6. INDEX (0) | 2025.04.25 |
|---|---|
| [ORACLE] 4. Lock & Latch (0) | 2025.04.22 |
| [ORACLE] Cursor (0) | 2024.04.17 |
| [ORACLE] SQL Parsing (0) | 2024.04.17 |
| [ORACLE] 3. Oracle Process (0) | 2023.03.06 |

